Learning Continuous 3D Words for Text-to-Image Generation
CVPR 2024
Publication date: June 19, 2024
Ta-Ying Cheng, Matheus Gadelha, Thibault Groueix, Matt Fisher, Radomír Měch, Andrew Markham, Niki Trigoni
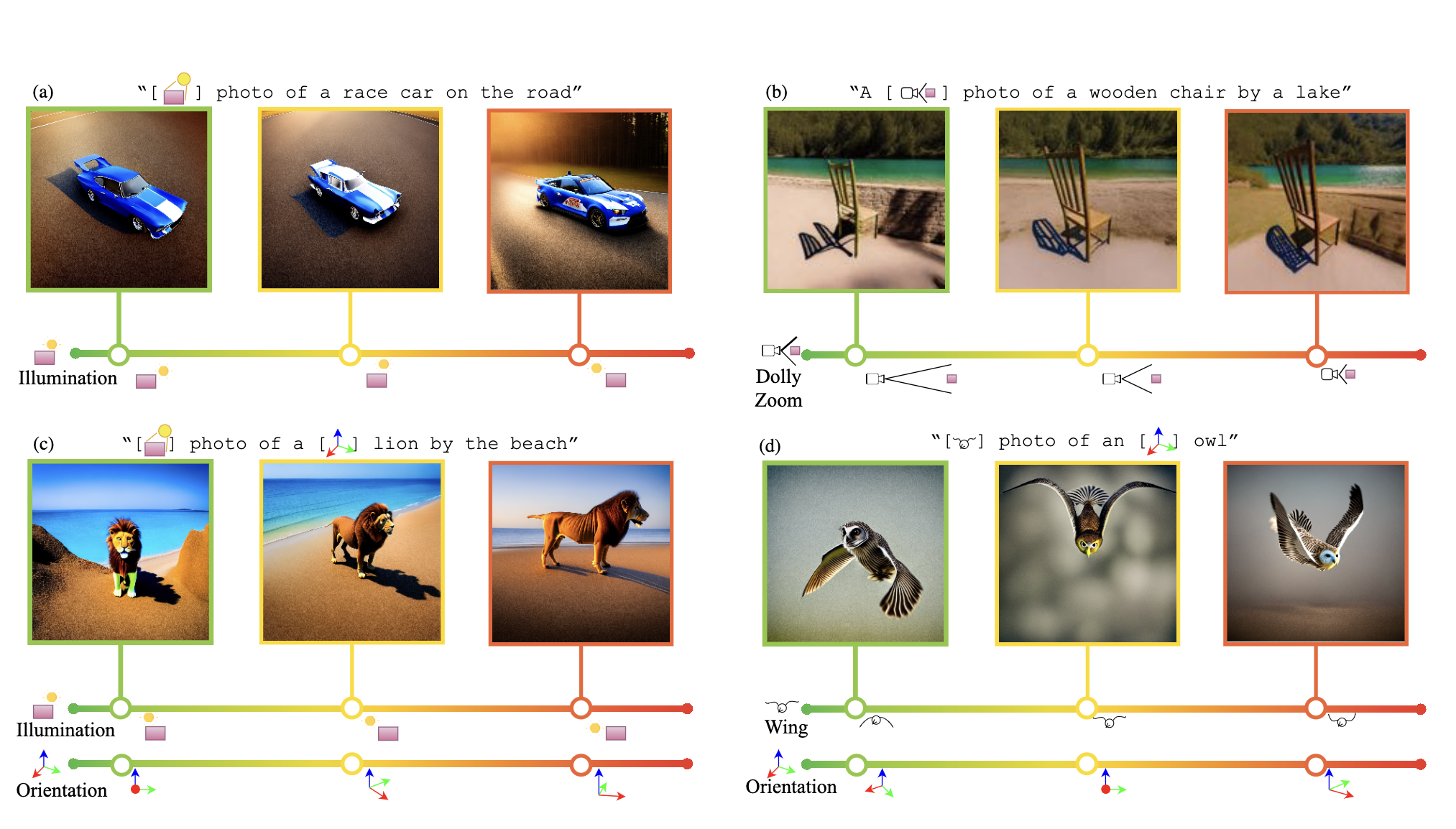
Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image. We do this by engineering special sets of input tokens that can be transformed in a continuous manner -- we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation. Given only a single mesh and a rendering engine, we show that our approach can be adopted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dollyzoom effect, and object poses. Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process.
Learn More