Adobe has been actively involved in the scientific advances and organization of the IEEE Computer Society International Conference on Computer Vision (ICCV) for years, and 2023 is no exception. From October 2 to 6 in Paris, our team will present 27 co-authored papers, including 24 technical papers, and 3 workshop papers. Adobe authors have also contributed to the conference in many other ways, including co-organizing several workshops, area chairing, and reviewing papers.
Many of Adobe’s co-authored papers are the result of internships and collaborations with university students and faculty. We are currently hiring for full-time positions. Please check out the Adobe Research Careers page to learn more.
See the list below to learn more about Adobe’s contributions to ICCV 2023.
Technical Papers
3DMiner: Discovering Shapes from Large-Scale Unannotated Image Datasets
Ta-Ying Cheng, Matheus Gadelha, Sören Pirk, Thibault Groueix, Radomír Měch, Andrew Markham, Niki Trigoni
Ablating Concepts in Text-to-Image Diffusion Models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, Jun-Yan Zhu
AssetField: Assets Mining and Reconfiguration in Ground Feature Plane Representation
Yuanbo Xiangli, Linning Xu, Xingang Pan, Nanxuan Zhao, Bo Dai, Dahua Lin
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Aishwarya Agarwal, Srikrishna Karanam, K J Joseph, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
Bring Clipart to Life
Nanxuan Zhao, Shengqi Dang, Hexun Lin, Yang Shi, Nan Cao
ContactGen: Generative Contact Modeling for Grasp Generation
Shaowei Liu, Yang Zhou, Jimei Yang, Saurabh Gupta, Shenlong Wang
Counterfactual-based Saliency Map: Towards Visual Contrastive Explanations for Neural Networks
Xue Wang, Zhibo Wang, Haiqin Weng, Hengchang Guo, Zhifei Zhang, Lu Jin, Tao Wei, Kui Ren
Efficient Adaptive Human-Object Interaction Detection with Concept-guided Memory
Ting Lei, Fabian Caba, Qingchao Chen, Hailin Jin, Yuxin Peng, Yang Liu
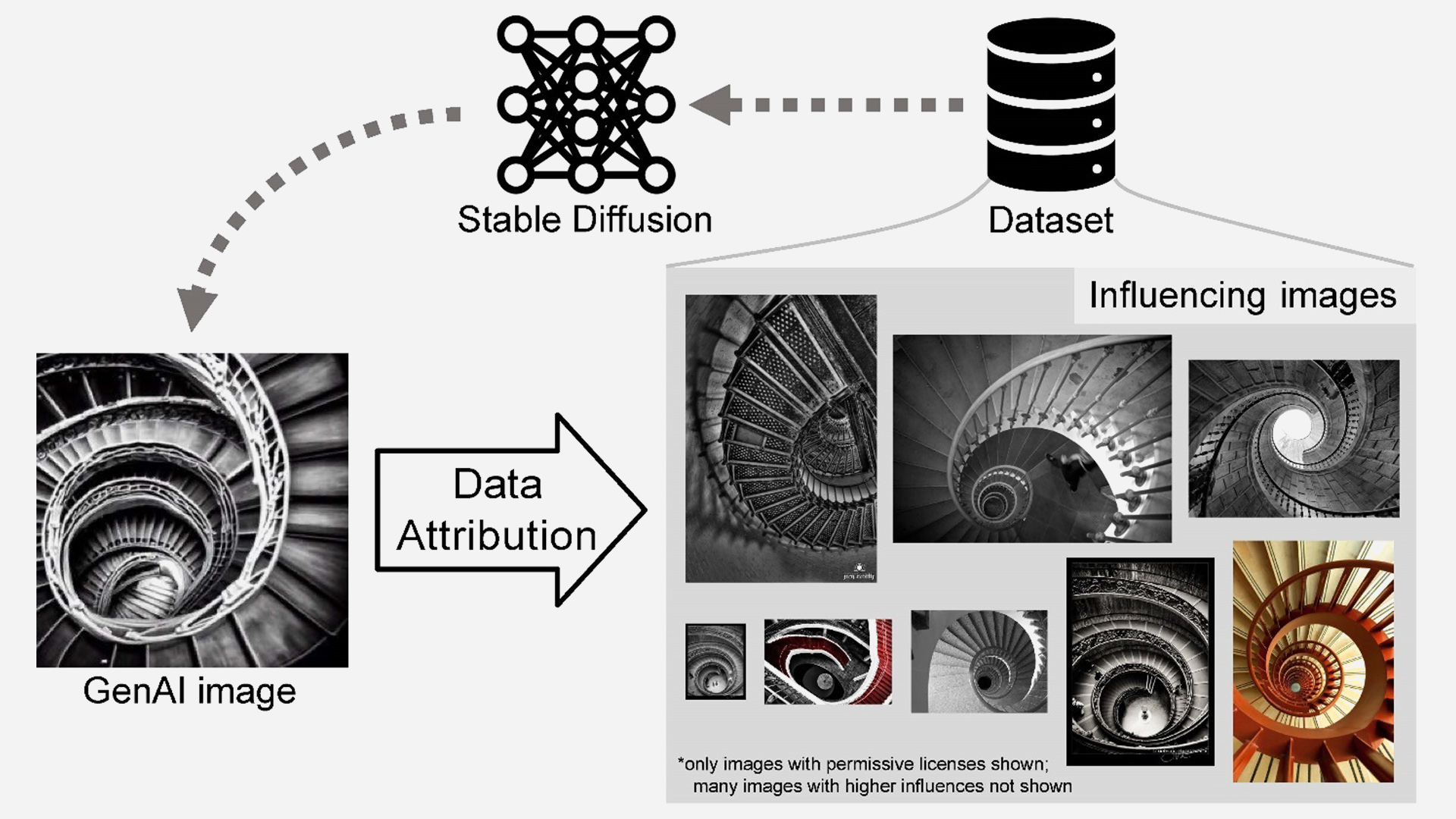
Evaluating Data Attribution for Text-to-Image Models
Sheng-Yu Wang, Alexei A. Efros, Jun-Yan Zhu, Richard Zhang
GAIT: Generating Aesthetic Indoor Tours with Deep Reinforcement Learning
Desai Xie, Ping Hu, Xin Sun, Sören Pirk, Jianming Zhang, Radomír Měch, Arie E. Kaufman
Harnessing the Spatial-Temporal Attention of Diffusion Models for High-Fidelity Text-to-Image Synthesis
Qiucheng Wu, Yujian Liu, Handong Zhao, Trung Bui, Zhe Lin, Yang Zhang, Shiyu Chang
Joint Implicit Neural Representation for High-fidelity and Compact Vector Fonts
Chia-Hao Chen, Ying-Tian Liu, Zhifei Zhang, Yuan-Chen Guo, Song-Hai Zhang
Learning Navigational Visual Representations with Semantic Map Supervision
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, Hao Tan
Localizing Moments in Long Video Via Multimodal Guidance
Wayner Barrios, Mattia Soldan, Alberto Mario Ceballos-Arroyo, Fabian Caba Heilbron, Bernard Ghanem
Long-range Multimodal Pretraining for Movie Understanding
Dawit Mureja Argaw, Joon-Young Lee, Markus Woodson, In So Kweon, Fabian Caba Heilbron
Moment Detection in Long Tutorial Videos
Ioana Croitoru, Simion-Vlad Bogolin, Samuel Albanie, Yang Liu, Zhaowen Wang, Seunghyun Yoon, Franck Dernoncourt, Hailin Jin, Trung Bui
Neural Video Depth Stabilizer
Yiran Wang, Min Shi, Jiaqi Li, Zihao Huang, Zhiguo Cao, Jianming Zhang, Ke Xian, Guosheng Lin
Pix2Video: Video Editing using Image Diffusion
Duygu Ceylan, Chun-Hao P. Huang, Niloy J. Mitra
Spatio-Temporal Crop Aggregation for Video Representation Learning
Sepehr Sameni, Simon Jenni, Paolo Favaro
Towards Fairness-aware Adversarial Network Pruning
Lei Zhang, Zhibo Wang, Xiaowei Dong, Yunhe Feng, Xiaoyi Pang, Zhifei Zhang, Kui Ren
Tracking Anything with Decoupled Video Segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, Joon-Young Lee
UMFuse: Unified Multi View Fusion for Human Editing Applications
Rishabh Jain, Mayur Hemani, Duygu Ceylan, Krishna Kumar Singh, Jingwan Lu, Mausoom Sarkar, Balaji Krishnamurthy
VADER: Video Alignment Differencing and Retrieval
Alexander Black, Simon Jenni, Tu Bui, Md. Mehrab Tanjim, Stefano Petrangeli, Ritwik Sinha, Viswanathan Swaminathan, John Collomosse
XMem++: Production-level Video Segmentation From Few Annotated Frames
Maksym Bekuzarov, Ariana Bermudez, Joon-Young Lee, Hao Li
Workshop Papers
CNOS: A Strong Baseline for CAD-based Novel Object Segmentation
Van Nguyen Nguyen, Thibault Groueix, Georgy Ponimatkin, Vincent Lepetit, Tomas Hodan
Online Detection of AI-Generated Images
David Epstein, Ishan Jain, Oliver Wang, Richard Zhang
Studying the Impact of Augmentations on Medical Confidence Calibration
Adrit Rao, Joon-Young Lee, Oliver Aalami
Workshop Co-organizers
The 5th Large-scale Video Object Segmentation Challenge
Joon-Young Lee
CVEU WORKSHOP
Fabian David Caba Heilbron
Area Chairs
Hailin Jin
Yijun Li
Jingwan Lu
Taesung Park
Zexiang Xu
Jimei Yang