CrossA11y: Identifying Video Accessibility Issues via Cross-modal Grounding
UIST 2022
Publication date: November 2, 2022
Xingyu "Bruce" Liu, Ruolin Wang, Dingzeyu Li, Xiang "Anthony" Chen, Amy Pavel
Best Paper Award
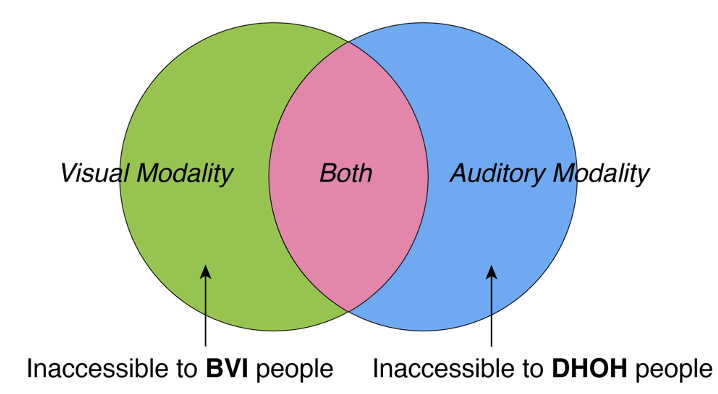
Authors make their videos visually accessible by adding audio descriptions (AD), and auditorily accessible by adding closed captions (CC). However, creating AD and CC is challenging and tedious, especially for non-professional describers and captioners, due to the difficulty of identifying accessibility problems in videos. A video author will have to watch the video through and manually check for inaccessible information frame-by-frame, for both visual and auditory modalities. In this paper, we present CrossA11y, a system that helps authors efficiently detect and address visual and auditory accessibility issues in videos. Using cross-modal grounding analysis, CrossA11y automatically measures accessibility of visual and audio segments in a video by checking for modality asymmetries. CrossA11y then displays these segments and surfaces visual and audio accessibility issues in a unified interface, making it intuitive to locate, review, script AD/CC in-place, and preview the described and captioned video immediately. We demonstrate the effectiveness of CrossA11y through a lab study with 11 participants, comparing to existing baseline.
Learn More