Adobe Research is presenting a total of 40 research papers on cutting-edge computer vision and AI topics at the 2020 Conference on Computer Vision and Pattern Recognition (CVPR) this week. 37 of the papers will be presented at the main conference, and three at the workshops.
Our researchers’ participation in this year’s virtual conference includes eight oral presentations, 29 poster presentations, eight area chair committee members, and numerous CVPR workshop co-chairs and presentations. Nearly all of Adobe Research’s papers are the results of student internships or other collaborations with university students and faculty.
CVPR, a top-tier computer vision conference in the research community, has attracted more than 6,500 registrants to the all-virtual event this year.
Here are the papers that Adobe Research is presenting at CVPR 2020:
Oral Presentations
AdaCoSeg: Adaptive Shape Co-Segmentation with Group Consistency Loss
Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J. Guibas, Hao Zhang
CNN-generated images are surprisingly easy to spot … for now
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, Alexei A. Efros
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Kyle Olszewski, Duygu Ceylan, Jun Xing, Jose Echevarria, Zhili Chen, Weikai Chen, Hao Li
Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF from a Single Image
Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, Manmohan Chandraker
Neural Cages for Detail-Preserving 3D Deformations
Wang Yifan, Noam Aigerman, Vladimir G. Kim, Siddhartha Chaudhuri, Olga Sorkine-Hornung
Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics
Simon Jenni, Hailin Jin, Paolo Favaro
Telling Left from Right: Learning Spatial Correspondence of Sight and Sound
Karren Yang, Bryan Russell, Justin Salamon
Video Panoptic Segmentation
Dahun Kim, Sanghyun Woo, Joon-Young Lee, In So Kweon
Poster Presentations
Active Speakers in Context
Juan Leon Alcazar, Fabian Caba, Long Mai, Federico Perazzi, Joon-Young Lee, Pablo Arbelaez, Bernard Ghanem
Affinity Graph Supervision for Visual Recognition
Chu Wang, Babak Samari, Vladimir G. Kim, Siddhartha Chaudhuri, Kaleem Siddiqi
Basis Prediction Networks for Effective Burst Denoising with Large Kernels
Zhihao Xia, Federico Perazzi, Michael Gharbi, Kalyan Sunkavalli, Ayan Chakrabarti
Collaborative Distillation for Ultra-Resolution Universal Style Transfer
Huan Wang, Yijun Li, Yuehai Wang, Haoji Hu, Ming-Hsuan Yang
Context-Aware Group Captioning via Self-Attention and Contrastive Features
Zhuowan Li, Quan Tran, Long Mai, Zhe Lin, Alan L. Yuille
Cross-Domain Document Object Detection: Benchmark Suite and Method
Kai Li, Curtis Wigington, Chris Tensmeyer, Handong Zhao, Nikolaos Barmpalios, Vlad I. Morariu, Varun Manjunatha, Tong Sun, Yun Fu
Deep 3D Capture: Geometry and Reflectance from Sparse Multi-View Images
Sai Bi, Zexiang Xu, Kalyan Sunkavalli, David Kriegman, Ravi Ramamoorthi
Deep Homography Estimation for Dynamic Scenes
Hoang Le, Feng Liu, Shu Zhang, Aseem Agarwala
Deep Parametric Shape Predictions using Distance Fields
Dmitriy Smirnov, Matthew Fisher, Vladimir G. Kim, Richard Zhang, Justin Solomon
DeepStrip: High Resolution Boundary Refinement
Peng Zhou, Brian Price, Scott Cohen, Gregg Wilensky, Larry S. Davis
Diverse Image Generation via Self-Conditioned GANs
Steven Liu, Tongzhou Wang, David Bau, Jun-Yan Zhu, Antonio Torralba
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Muyang Li, Ji Lin, Yaoyao Ding, Zhijian Liu, Jun-Yan Zhu, Song Han
Generative-discriminative Feature Representations for Open-set Recognition
Pramuditha Perera, Vlad I. Morariu, Rajiv Jain, Varun Manjunatha, Curtis Wigington, Vicente Ordonez, Vishal M. Patel
Going Deeper with Point Networks
Eric-Tuan Le, Iasonas Kokkinos, Niloy J. Mitra
How much time do you have? Modeling multi-duration saliency
Camilo Fosco, Anelise Newman, Pat Sukhum, Yun Bin Zhang, Nanxuan Zhao, Aude Oliva, Zoya Bylinskii
Learning a Neural 3D Texture Space from 2D Exemplars
Philipp Henzler, Niloy J. Mitra, Tobias Ritschel
Learning Generative Models of Shape Handles
Matheus Gadelha, Giorgio Gori, Duygu Ceylan, Radomir Mech, Nathan Carr, Tamy Boubekeur, Rui Wang, Subhransu Maji
Learning Visual Emotion Representations from Web Data
Zijun Wei, Jianming Zhang, Zhe Lin, Joon-Young Lee, Niranjan Balasubramanian, Minh Hoai, Dimitris Samaras
MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks
Animesh Karnewar, Oliver Wang
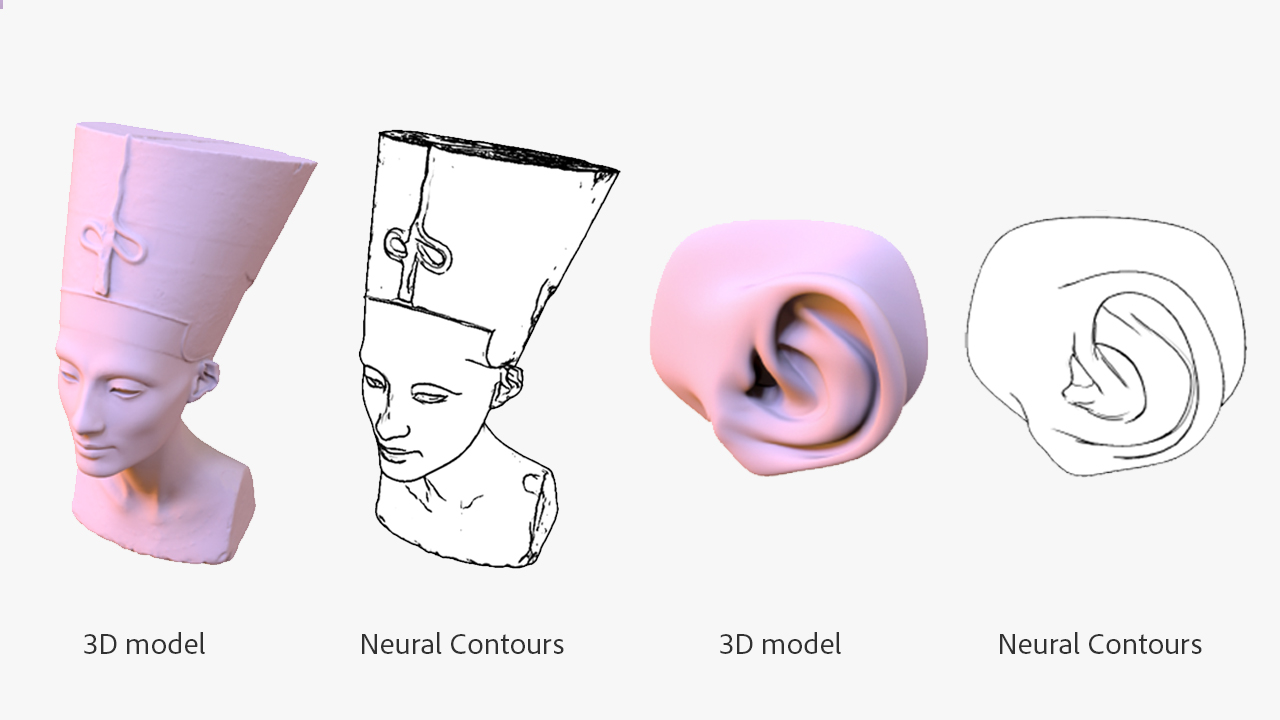
Neural Contours: Learning to Draw Lines from 3D Shapes
Difan Liu, Mohamed Nabail, Aaron Hertzmann, Evangelos Kalogerakis
PhraseCut: Instance-Aware Segmentation from Natural Language
Chenyun Wu, Zhe Lin, Scott Cohen, Trung Bui, Subhransu Maji
Screencast Tutorial Video Understanding
Kunpeng Li, Chen Fang, Zhaowen Wang, Seokhwan Kim, Hailin Jin, Yun Fu
SDC-Net: Semantic Divide-and-Conquer Network for Monocular Depth Estimation
Lijun Wang, Jianming Zhang, Oliver Wang, Zhe Lin, Huchuan Lu
Sketchformer: Transformer-based Representation for Sketched Structure
Leo Sampaio Ferraz Ribeiro, Tu Bui, John Collomosse, Moacir Ponti
StructEdit: Learning Structural Shape Variations
Kaichun Mo, Paul Guerrero, Li Yi, Hao Su, Peter Wonka, Niloy J. Mitra, Leonidas Guibas
Structure-Guided Ranking Loss for Single Image Depth Prediction
Ke Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, Zhiguo Cao
Superpixel Segmentation with Fully Convolutional Networks
Fengting Yang, Qian Sun, Hailin Jin, Zihan Zhou
Temporally Distributed Networks for Fast Video Semantic Segmentation
Ping Hu, Fabian Caba, Oliver Wang, Zhe Lin, Stan Sclaroff, Federico Perazzi
Unsupervised Learning of Intrinsic Structural Representation Points
Nenglun Chen, Lingjie Liu, Zhiming Cui, Runnan Chen, Duygu Ceylan, Changhe Tu, Wenping Wang
Workshop Presentation
Challenges in Recognizing Spontaneous and Intentionally Expressed Reactions to Positive and Negative Images
Jennifer Healey, Haoliang Wang, Niyati Chhaya
Deep Audio Prior: Learning Sound Source Separation from a Single Audio Mixture
Yapeng Tian, Chenliang Xu, Dingzeyu Li
Weakly-Supervised Audio-Visual Video Parsing Toward Unified Multisensory Perception
Yapeng Tian, Dingzeyu Li, Chenliang Xu