Audio researchers at Adobe co-authored 19 papers at top-tier conferences and journals in 2022. In addition to audio research published at venues such as ICASSP, INTERSPEECH and IWAENC, Adobe researchers work at the intersection of audio and areas such as computer vision and human-computer interaction, leading to publications in CVPR, UIST, and high-impact journals. These publications covered a range of topics in audio AI with applications to speech, music, and everyday sounds including enhancement, editing, audio production, accessibility, and recommendation.
Adobe researchers also served as chairs and committee members at audio conferences including ICASSP and ISMIR, and served on organization boards and committees such as the IEEE Audio and Acoustic Signal Processing Technical Committee and the ISMIR Society board.
Most of the Adobe co-authored papers are the outcome of research internships. Please check out the Adobe Research careers page to learn more about internships and full-time career opportunities.
ICASSP 2022
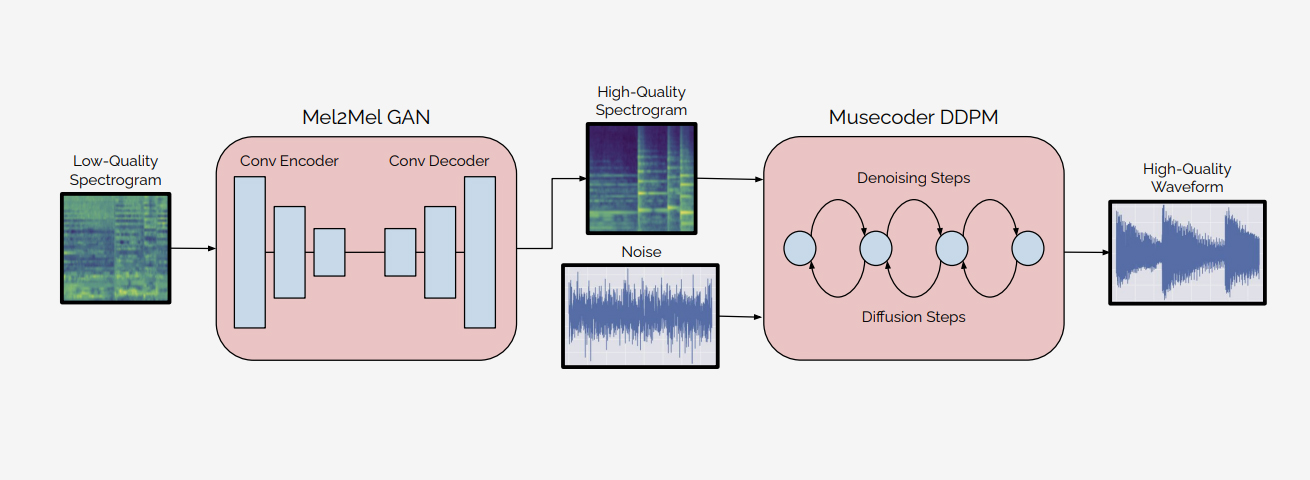
Music Enhancement Via Image Translation and Vocoding
Nikhil Kandpal, Oriol Nieto, Zeyu Jin
Controllable Speech Representation Learning Via Voice Conversion and AIC Loss
Yunyun Wang, Jiaqi Su, Adam Finkelstein, Zeyu Jin
SQAPP: No-Reference Speech Quality Assessment via Pairwise Preference
Pranay Manocha, Zeyu Jin, Adam Finkelstein
Don’t Separate, Learn to Remix: End-to-End Neural Remixing with Joint Optimization
Haici Yang, Shivani Firodiya, Nick Bryan, Minje Kim
End-to-end Neural Coreference Resolution Revisited: A Simple yet Effective Baseline
Tuan Manh Lai, Trung Bui, Doo Soon Kim
INTERSPEECH 2022
DocLayoutTTS: Dataset and Baselines for Layout-informed Document-level Neural Speech Synthesis
Puneet Mathur, Franck Dernoncourt, Quan Hung Tran, Jiuxiang Gu, Ani Nenkova, Vlad Morariu, Rajiv Jain, Dinesh Manocha
Audio Similarity is Unreliable as a Proxy for Audio Quality
Pranay Manocha, Zeyu Jin, Adam Finkelstein
Filler Word Detection and Classification: A Dataset and Benchmark
Ge Zhu, Juan-Pablo Caceres, Justin Salamon
Span Classification with Structured Information for Disfluency Detection in Spoken Utterances
Sreyan Ghosh, Sonal Kumar, Yaman Kumar, Rajiv Ratn Shah, Srinivasan Umesh
Other Venues (IWAENC, CVPR, UIST, PMLR, JAE, TASLP, JAES)
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Junkai Wu, Jonah Casebeer, Nicholas Bryan, Paris Smaragdis
Published at IWAENC 2022 conference, June 2022
It’s Time for Artistic Correspondence in Music and Video
Dídac Surís, Carl Vondrick, Bryan Russell, Justin Salamon
Published at CVPR 2022 conference, June 2022
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Yang Zhou, Jimei Yang, Dingzeyu Li, Jun Saito, Deepali Aneja, Evangelos Kalogerakis
Published at CVPR 2022 conference, June 2022
Record Once, Post Everywhere: Automatic Shortening of Audio Stories for Social Media
Bryan Wang, Zeyu Jin, Gautham Mysore
Published at UIST 2022 conference, October 2022
CrossA11y: Identifying Video Accessibility Issues via Cross-modal Grounding
Xingyu “Bruce” Liu, Ruolin Wang, Dingzeyu Li, Xiang “Anthony” Chen, Amy Pavel
Published at UIST 2022 conference, October 2022
Best Paper Award
Beyond Subtitles: Captioning and Visualizing Non-speech Sounds to Improve Accessibility of User-Generated Videos
Oliver Alonzo, Hijung Valentina Shin, Dingzeyu Li
Published at ASSETS 2022 conference, October 2022
HEAR: Holistic Evaluation of Audio Representations
Joseph Turian, Jordie Shier, Humair Raj Khan, Bhiksha Raj, Björn W. Schuller, Christian J. Steinmetz, Colin Malloy, George Tzanetakis, Gissel Velarde, Kirk McNally, Max Henry, Nicolas Pinto, Camille Noufi, Christian Clough, Dorien Herremans, Eduardo Fonseca, Jesse Engel, Justin Salamon, Philippe Esling, Pranay Manocha, Shinji Watanabe, Zeyu Jin, Yonatan Bisk
Published in Proceedings of Machine Learning Research (PMLR), December 2022.
Automated Acoustic Monitoring Captures Timing and Intensity of Bird Migration
Benjamin M. Van Doren, Vincent Lostanlen, Aurora Cramer, Justin Salamon, Adriaan Dokter, Steve Kelling, Juan Pablo Bello, Andrew Farnsworth
Published in Journal of Applied Ecology, December 2022
Style Transfer of Audio Effects with Differentiable Signal Processing.
Christian J. Steinmetz, Nicholas Bryan, Joshua D. Reiss
Published in Journal of the Audio Engineering Society (JAES), September 2022
Meta-AF: Meta-learning for Adaptive Filters
Jonah Casebeer, Nicholas Bryan, Paris Smaragdis
Published in IEEE Transactions on Audio, Speech, and Language Processing (TASLP), November 2022