
Part 3: Neural Stylization
by Aaron Hertzmann, Adobe Research
This is the third and final blog post in a series of three posts on the history of image stylization algorithms. The first post described early procedural methods for stylization, and the second post described the first example-based stylization methods, which were based on patch-based algorithms.
In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton at University of Toronto demonstrated state-of-the-art performance on image recognition using deep neural networks, setting off an enormous surge of creativity and energy around AI using deep learning. Although deep networks had been developed over the past decades by Hinton, LeCun, and others, their sudden success was now only possible, in part, because of the development of the original ImageNet classification dataset by Jia Deng and Fei-Fei Li at Stanford, with many collaborators and crowdworkers. The new neural networks seemed to be a general-purpose tool for all sorts of vision problems. These networks learned rich “features” describing the statistics of natural images from this large dataset.
Hence, in 2015, Leon Gatys, then a neuroscience graduate student at University of Tübingen, revisited the texture synthesis question, which I described in the previous post. Could the new deep network features explain human texture perception?
With his collaborators Matthias Bethge and Alexander Ecker, Gatys began from the approach of Portilla and Simoncelli that I described in the previous post, but simplified the statistical representation (using only correlation statistics) but applied them to the much-richer deep networks. The synthesis results they got were really impressive:
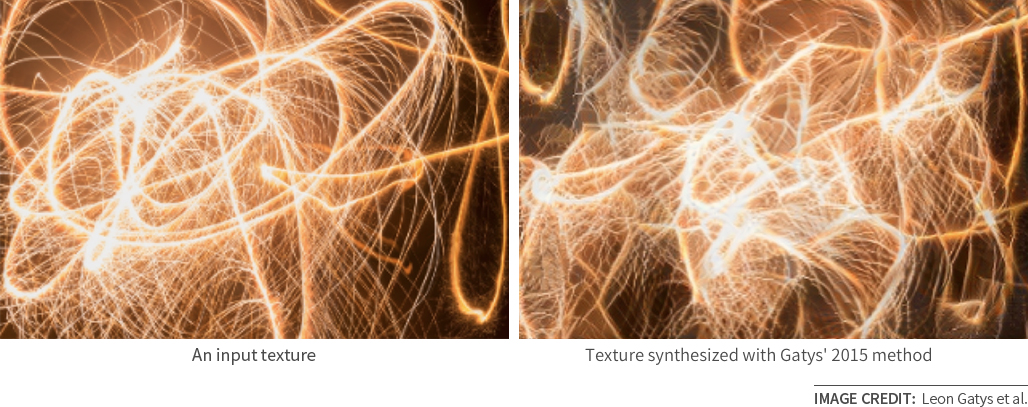
It was hard to imagine the patch-based methods being able to create such complex structures so seamlessly. Simply by using these new representations, they were able to dramatically improve on previous texture synthesis algorithms, capturing various large-scale structures that we might not have even thought of as “texture.” (They later found that random weights in a simpler networks also worked as well as ImageNet-trained features for texture synthesis, indicating that it is either the neural network architecture —or perhaps the sheer number of correlations—and not the training data that is important in this representation.)
Neural Image Stylization
Having discovered that neural network features could capture texture so well, Gatys and his collaborators asked: could neural networks also work for image stylization?
Their approach was as follows. Starting from a photograph and painting, their goal was to produce an image with the texture of the painting, but the overall “content” of the photograph. This meant a numerical optimization problem to balance these goals. Running this optimization produced a result like this:

This is the “Starry Night” (1889) image that the original Image Analogies algorithm would perform poorly on.
Since their paper was first posted online in August 2015, an enormous amount of energy and excitement followed. Several fast neural stylization methods were published, in which a neural network is directly trained to produce the output that Gatys’ slower algorithm would have produced. For example, the WCT method can efficiently transfer new styles without requiring any training. Mobile apps that apparently implemented versions of this method appeared not long afterward. Versions of this algorithm are implemented in several popular apps like Prisma and Facebook Live Video. Together with Gatys, we developed methods for preserving image color in his method (using a color transfer method from Image Analogies), as well as controlling spatial and scale variations in style. Moreover, it has inspired renewed interest in image stylization as a research area, as well as contributed to discussions around the role of artificial intelligence in producing art.

This work has led to many other new ideas as well. Other colleagues at Adobe and Cornell have shown how to apply these methods to photorealistic style transfer:

Numerous new extensions to these ideas are being published regularly.
Image Translation Revisited
A more general problem statement is to learn image transformations from a large collection of paired examples. The pix2pix algorithm, from Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alyosha Efros at UC Berkeley, takes a collection of before/after pairs as input, and trains a neural network to learn to transform one to the other. They were inspired in part by neural networks’ success at natural language translation tasks. Their method can use much more information than the previous neural stylization and analogies algorithms, because it is trained from larger datasets and thus sees many before-and-after examples. It also makes use of the recent Generative Adversarial Network (GAN) loss to improve the image quality.

However, pix2pix does make the restriction that you need to supply carefully-paired before/after training examples.
One of the most intriguing recent ideas is the CycleGAN, which shows how to train image transformation algorithms from collections of before images and after images without requiring correspondences. That is, you can train to convert images of southern France to Monet paintings, without ever needing a photograph to go with each of the Monet training paintings.

In the short time since this was published, there have been several significant follow-ups to handle the cases of multimodal transformation, when one input image could have several outputs, including interactive image colorization, BicycleGAN, and MUNIT. New improvements and applications are appearing regularly.
Where Are We At?
The recent progress in neural stylization has been exhilarating: so many new results, applications, and insights around artistic image synthesis have appeared in a short amount of time, when not a whole lot had been happening for years beforehand. Through new apps and media attention, the idea of computer-generated paintings is reaching the public consciousness in a new way, and people are starting to ask how these tools transform artwork.
However, despite their initial wow-factor, the recent neural stylization methods are quite limited in some ways. If you’re looking for a cool stylization for your profile pictures or Instagram posts, they’re great. On the other hand, the neural methods give very limited control to a professional user that may wish to direct or control the output, something which is much easier with procedural and patch-based methods.
When inspecting the results from neural stylization, there are many visible artifacts: things that the original artists probably would not have done. For example, scene elements from the example appear in the target (e.g., starry night elements showing up a daytime scene). Scene contours and outlines are often broken up in unnatural ways. The CycleGAN is one potential solution to some of these issues, since it can potentially learn from large, unpaired datasets, but it hasn’t been shown in general cases yet. And, although there have been numerous research papers improving the quality and generality of fast stylization, these methods generally have results that don’t even look as good as Gatys’ slower method.
In general, while all of these method create results that are amazing, they still fall far short of what the original artists would do. It seems hard to imagine that, had Van Gogh visited Tübingen during the day, that he would have used the same colors and elements of his Starry Night. Of course, matching the original artists’ output is an unrealistic bar to set. A more realistic goal is to match the quality of what procedural computer graphics algorithms can achieve for 3D models, and we are not there yet either. As examples, here are two procedural graphics algorithms that achieve many styles that example-based stylization methods currently cannot (e.g., see the results in this video).
At present, all existing image stylization algorithms are “just texture.” As we saw at the start of this article, both Image Analogies and Neural Stylization arose from generalizations of texture synthesis algorithms, and they still are about “surface appearance” rather than responding to scene content. In contrast, many of the older procedural methods are able to leverage higher-level concepts like object geometry and object identities.
Finally, although neural stylization has attracted the most attention lately, it’s worth noting that patch-based stylization methods (e.g., Image Analogies) can often give better results than neural stylization. Here is an example from the StyLit paper:

The Deep Image Analogies method has also shown extremely impressive stylization results, for cases where both images have very similar content. Both methods seem to have advantages: neural stylization seems to generalize better, but patch-based methods seem to work better when the example and targets are more similar. It is also unknown how to interpret the neural style methods; for example, do they copy patches, interpolate patches, somehow create entirely new patches?
For the time being, all these approaches have something to offer when trying to develop new algorithms. Furthermore, the insights from the old procedural methods have yet to be incorporated into the latest methods. Given how much progress has been made in the past two years, I’m excited to see what comes next!
Acknowledgments. Thanks to Meredith Kunz for help with this post, and to the following for their comments on drafts: Alex Berg, Phillip Isola, Leon Gatys, Eli Schechtman, Eero Simoncelli, Holger Winnemöller, Jimei Yang, and Jun-Yan Zhu.